编码的理解
简介
编码本身其实不是什么难以理解的东西,就是将想要编码的东西与自然数形成一一对应的过程。编码本身没什么可学的东西,但是我们却总会别乱码所困扰,理解原理是解决乱码的前提,所以开始我们的学习之旅吧。
几种编码
目前常见的编码有三种,ASCII、ANSI(扩展ASCII)和Unicode。ASCII是几乎所有编码都兼容的存在,ANSI多用于Window和Mac系统,Unicode则多用于类Unix系统如linux和安卓。
ASCII编码
ASCII码共有128个字符,0~31和127(注意从0开始的话127就是最后一个)为控制字符,如换行(\n),回车(\r)等,32~126为打印字符,包括空格(32),数字0-9(48~57),大写字母A-Z(65~90),小写字母a-z(97~122)等,实际上ASCII对应了电脑键盘上几乎所有的字符(比较特别的如F1~F14),可以近似认为ASCII即是键盘的编码。
编码最终都是要存储到计算机里,计算机里面只要二进制,不过十进制与二进制有天生的对应关系,这并非我们需要考虑的。因为二进制的特性,2^n比较适合当计算机中的“整数”,而比较巧的是128正好等于2^7,实际可能是反过来,于是可以通过7个二进制位来存储这些数据。不过伟大的编码人员好像考虑到了扩展性,决定在之前加一个二进制位以备不时之需,这样就可以以8个二进制位来存储ASCII编码的字符,其中最高位为0。这样做有许多好处,首先二进制可以很容易的转化为8(2^3)进制和16(2^4)进制,如2进制转为16进制可以每四个的进行转化,其次可以在最高位填1来进行ASCII的扩展,这也有助于让基本所有的编码都兼容ASCII编码。最后总结一下ASCII编码方式,控制字符(0x00-0x1F和0x7F,000-037和0177)和打印字符(0x20-0x7E,0040-0176),可以看到十分优良的性质,8个二进制位对应3个八进制位对应2个十六进制位。
ANSI编码
ANSI是ASCII的扩展,但并不是具体的编码方式,而是依据不同的国家语言有不同的实现,主要存在于Windows等系统里,如简体中文用GBK,日语用Shift_JIS,繁体中文用Big5等,其主要是因为字符的差异,还包括标点。但它们还有一些共性,如都与ASCII兼容,此部分占一个字节,其余字符最多两个字节,占的编码区为0x80~0xFFFF,且不同ANSI编码间互不兼容。有一点十分不友好的是,VisualStudio的默认编码是ANSI,我们可以做个实验来验证它,如下:
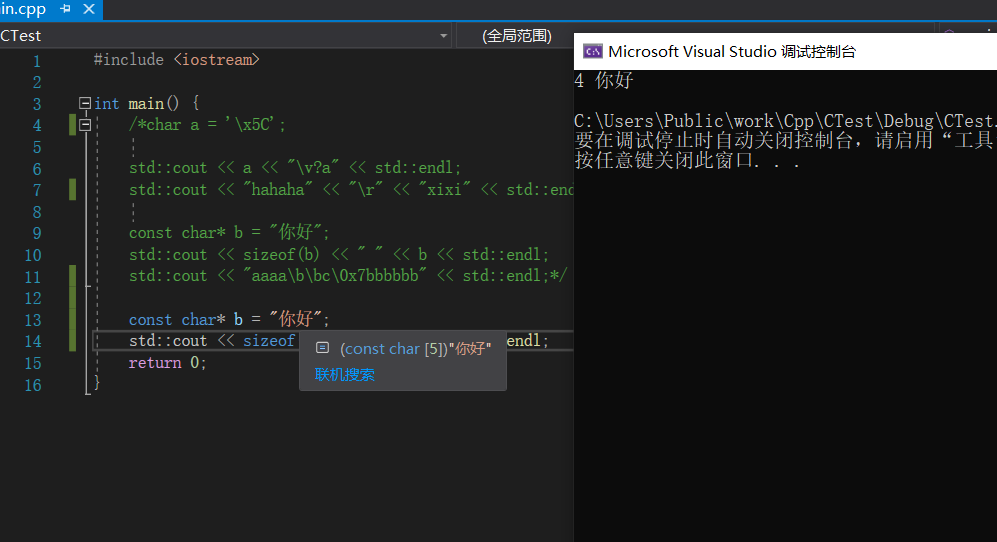
我们可以看到字符“你好”占了5个字节,一个中文两字节,加上字符串结尾的“\0”
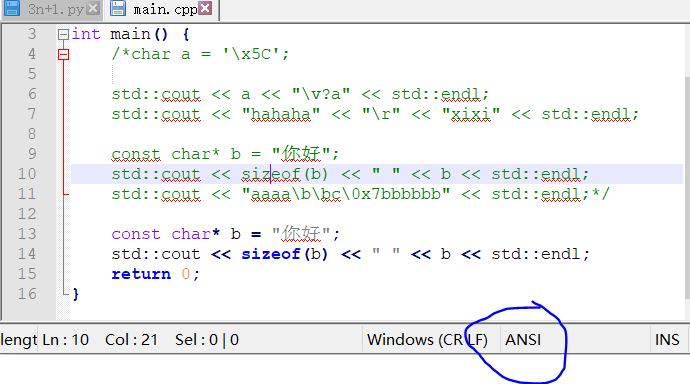
我们打开nodepad++,
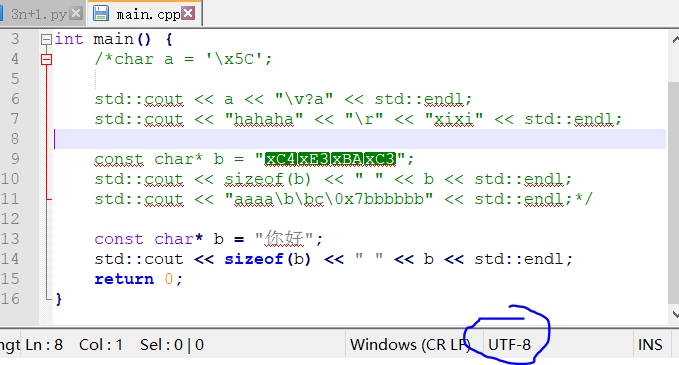
修改编码为UTF-8后再输入“你好”,注意看上面“\x”开头的是原始编码的“你好”,转回我们的VS编辑器
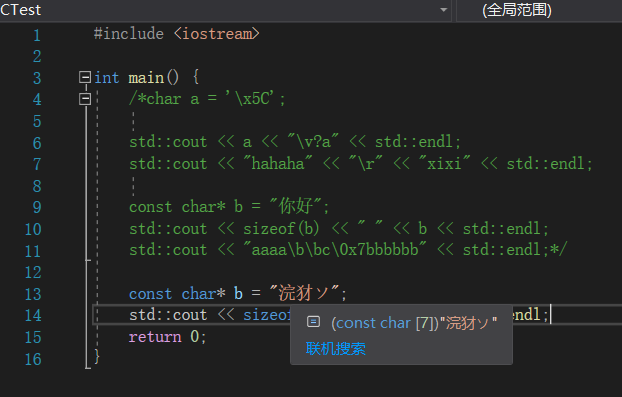
字符已经发生了改变,不包括结尾占用6个字节,实际上我们可以通过命令行来改变输出的编码
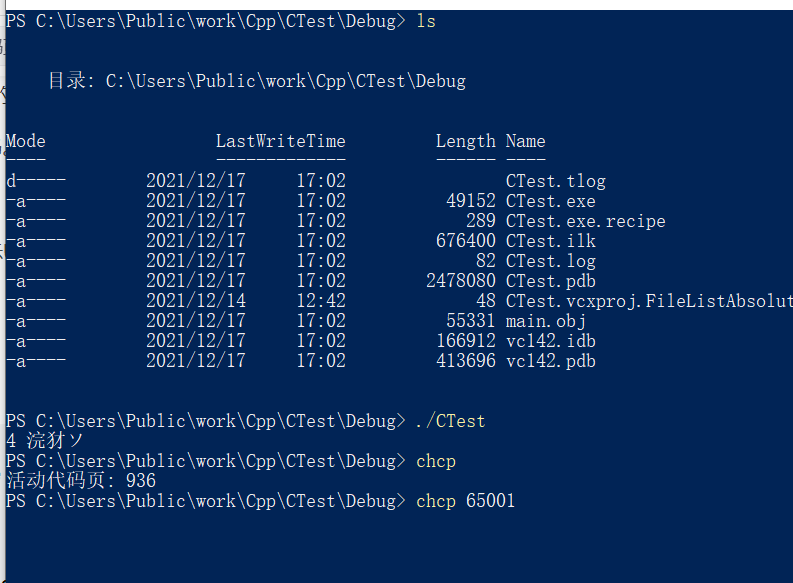
确定原始的输出,确实存在乱码
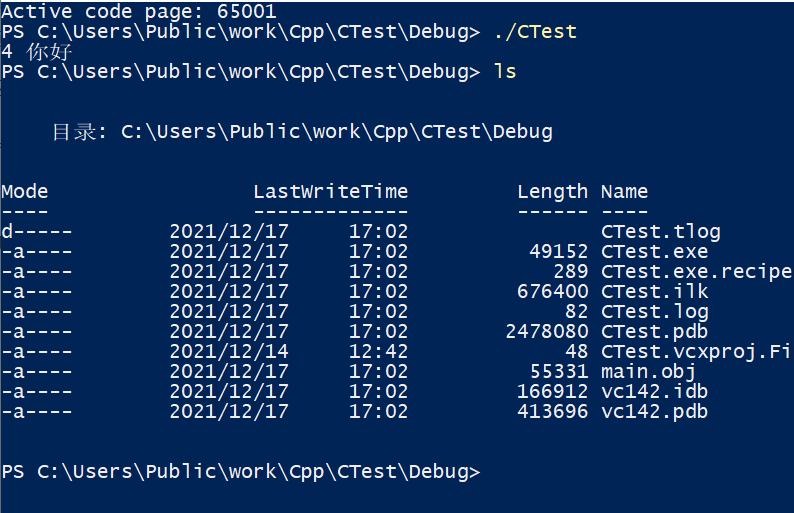
我们通过chcp来改变命令行的编码(注意这是Windows才有的,linux要通过改变环境变量来实现),最终输出了正确结果。
还有如我们有时玩的日语小黄游,部分是在Windows上开发的,默认使用的都是ANSI编码,在日本即是Shift_JIS,我们平常使用的Windows也一样,但因为在中国,所以使用的是GBK编码,又因为两者不兼容,因此我们的许多黄油都是乱码的,当然一般是在UI层面,如果基于有些引擎的话,一般会内置语言模块,使用通用编码Unicode,所有一般不会出现问题。你问我为什么英语软件不会乱码?它们可是万物兼容的ASCII,当然不会乱码了。对于我而言微软的Windows系统还是有许多槽点的,如使用BOM编码来标记文本,说难听一点Windows把用户当“傻子”,提供无微不至的关爱。实际上,Windows后来也妥协使用了Unicode字符集,但因为原始的积累终究还是没能与UTF-8这种常用编码对接,实属可惜。
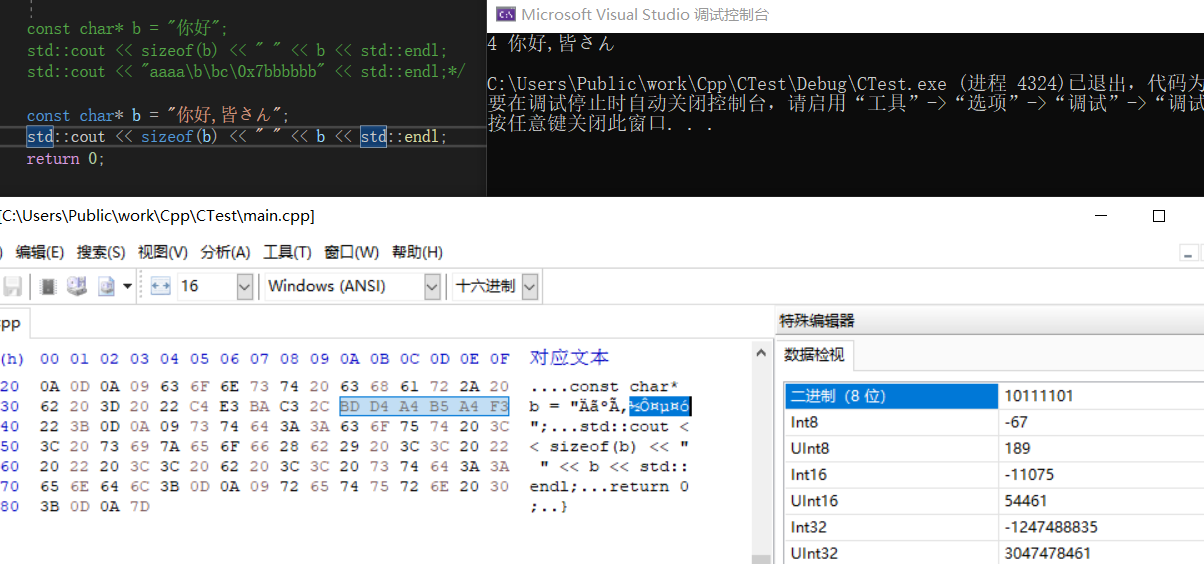
如果我把系统语言改为日语,就会像下面这样
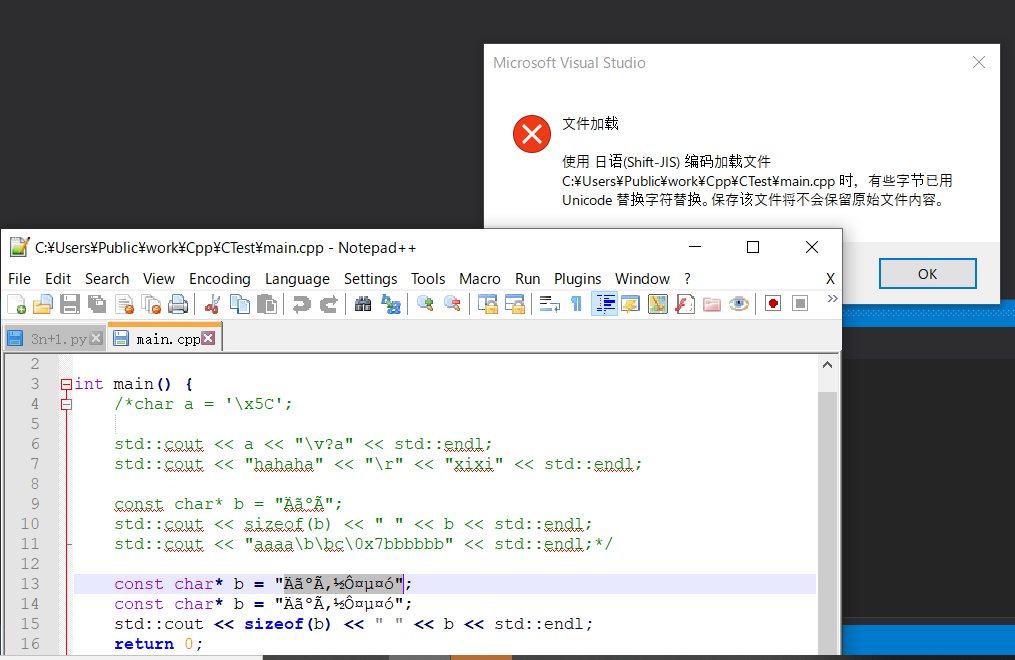
为什么对话框有中文,是因为VS安装时使用的是中文,注意nodepad++顶部的路径使用¥代替\是日语的特色
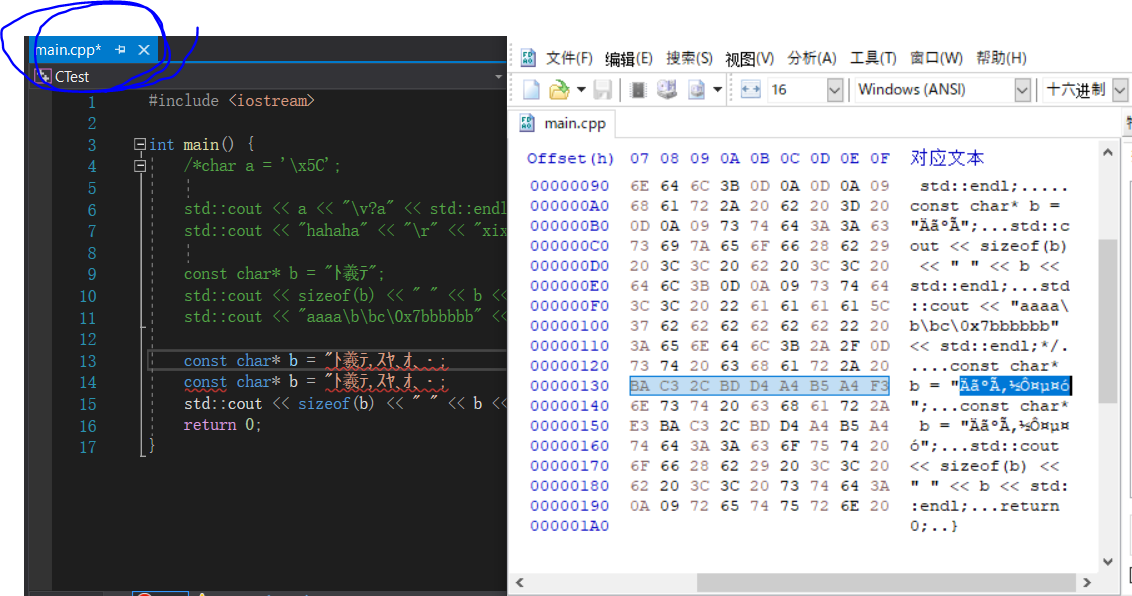
进一步从十六进制编辑器我们可以看到,底层文本的存储内容其实是相同的。
Unicode编码
身为开发者,考虑国际化的话,记住一定要使用Unicode编码。Unicode基于通用字符集几乎将所有国家的字符都进行了统一编码,范围覆盖0-0x10FFFF,总之要想在文本里混合各种语言不使用Unicode基本做不到。“0-0x7F”对于ASCII码,“0x600-0x6FF”阿拉伯文,“0x1100-0x11FF”朝鲜字母,“0x3040-0x30FF”日文假名,“0x4E00-0x9FFF”CJK表意文字包括中文,等等,实际上到“0xFFF0-0xFFFF”特殊就基本算完结了,后面的扩充平面到现在也没用过。但Unicode只是一个字符集到自然数的映射方案,并非具体实现,因为我们还要考虑程序读取的问题,到底要读取几个字节作为一个字符。
UTF-8编码
这种编码是使用最频繁的一种,主要是此种编码与ASCII兼容使用了ASCII的预留位,同时还是可变长度,如同样的ASCII字符用UTF-16编码占两个字节,用UTF-8则占一个字节,但一个中文字符在UTF-8里却占三个字节,在UTF-16里则占两个字节,希腊字母在UTF-8和UTF-16里都是两个字节,但是两者存储内容并不相同。UTF-8所占字节从1-4不等,如下,00-7F(1字节),C2-DF 80-BF(2字节)等,实际第一个十六进制位的范围即可确定字节数,0-7(0000-0011),8-D(0100-1101),E(1110),F(1111)。
UTF-16编码
UTF-16的所有编码内容都是2字节,所以与ASCII并不兼容,不过在java内部使用的就是这种编码,所以java可以使用丰富的语言,同时每个char都是两个字节。与UTF-8不同,UTF-8实际上有些内容并没有编码而用于方便程序识别长度,所以虽然灵活,但内容利用不充分,UTF-16则不同,与此同时UTF-16还得考虑字节序的问题,由此得到UTF-16BE(大端)和UTF-16LE(小端),以下是大小端存储的例子

然后是大端读取(这一般是默认的)

小端读取

至于其它的编码都不怎么用,就不讲了。
程序设计中的编码
C/C++
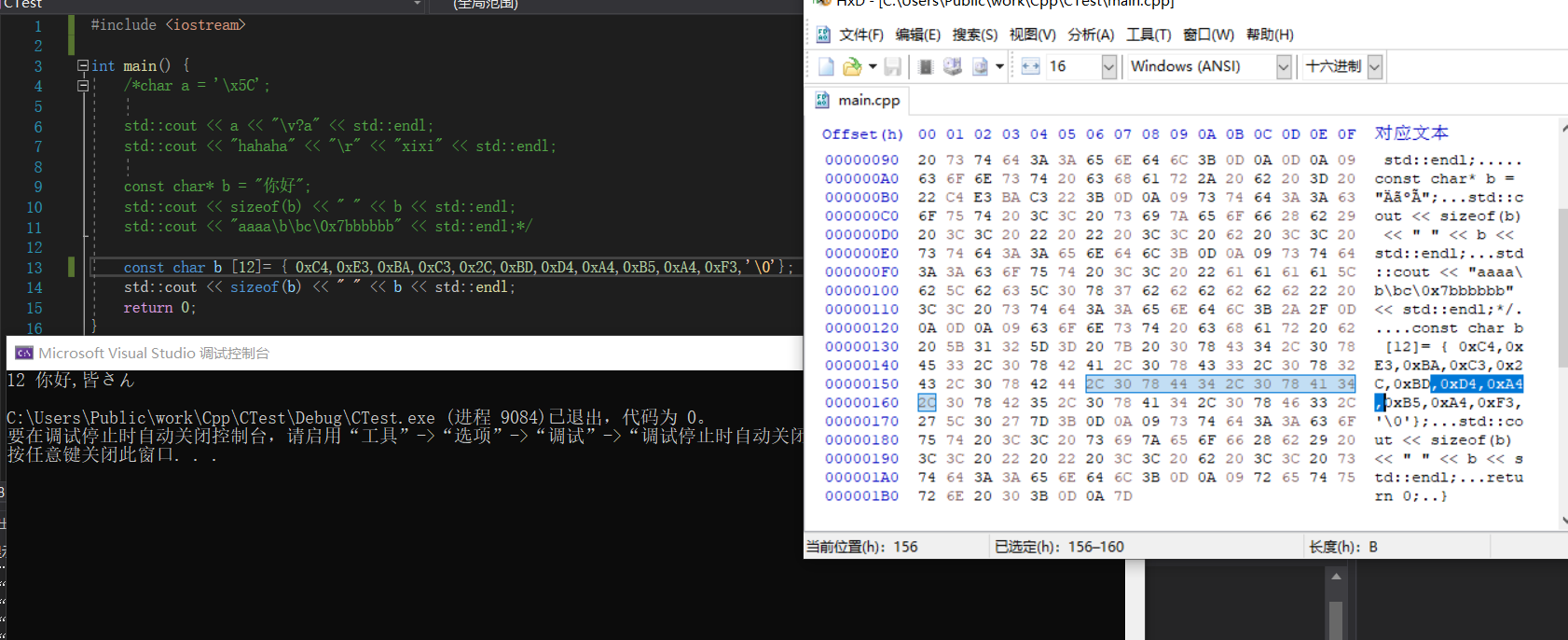
C/C++使用的是原生字节存储字符,即C/C++在识别到“”时,会将内部的内容直接以字节保存,所有C/C++并没有byte类型,同时char也只有1个字节,注意从存储字符的意义上来讲unsigned char和char本质是相同的,因为符号位在最高二进制位,字符所处区间的最高二进制位都为0,所以两者是一样的。我们可以更进一步的理解,我们把中文的每个字节抠出来再输出,结果如下
java
java对于字符的内部存储使用的是UTF-16,与C/C++不同java基于这种方式提供了丰富的字符功能,C/C++里面的char对应java的应该是byte而不是java里面的char。但是如果你真的用UTF-16来写代码编译是无法通过的
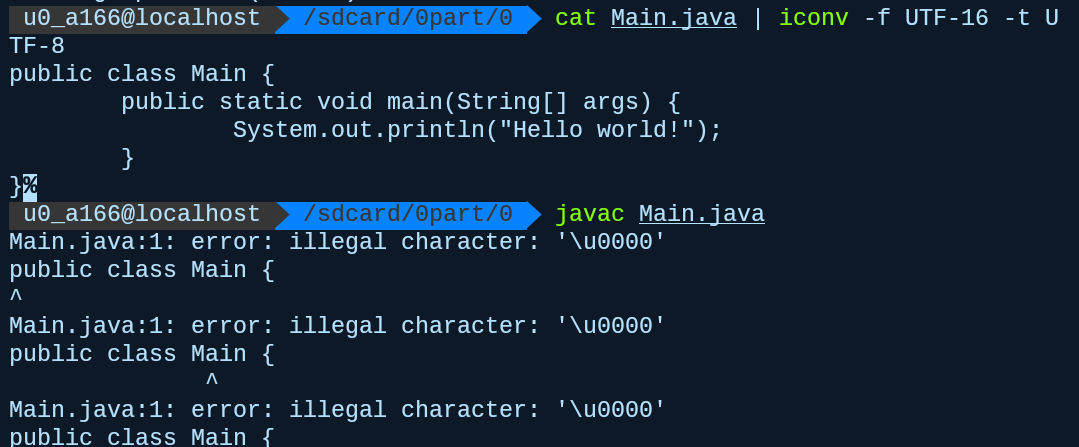
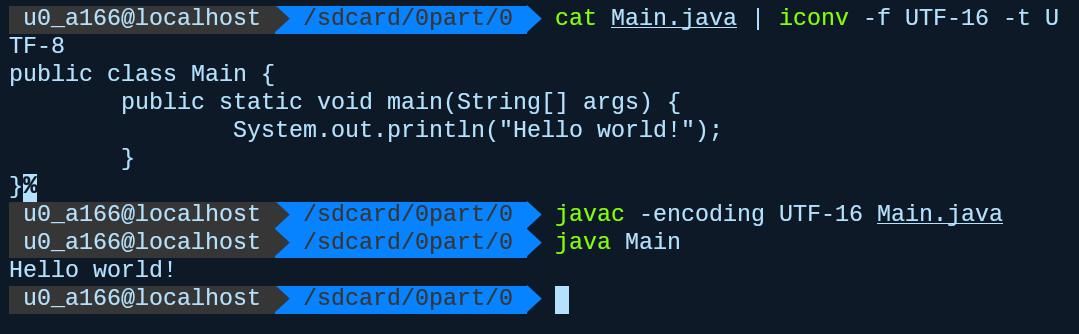
java编译读取默认使用的UTF-8,虽然我们可以通过调节参数来实现正常编译,但我们并不推荐这样做
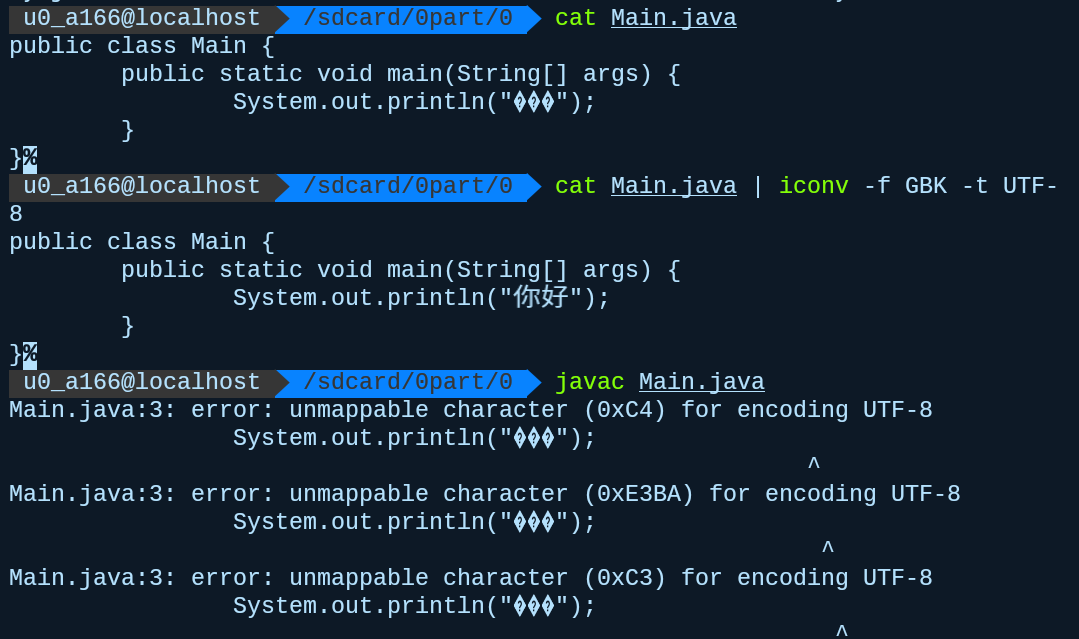
如何证明java内部存储使用的是UTF-16,可以使用一个序列化输入流实现,代码如下
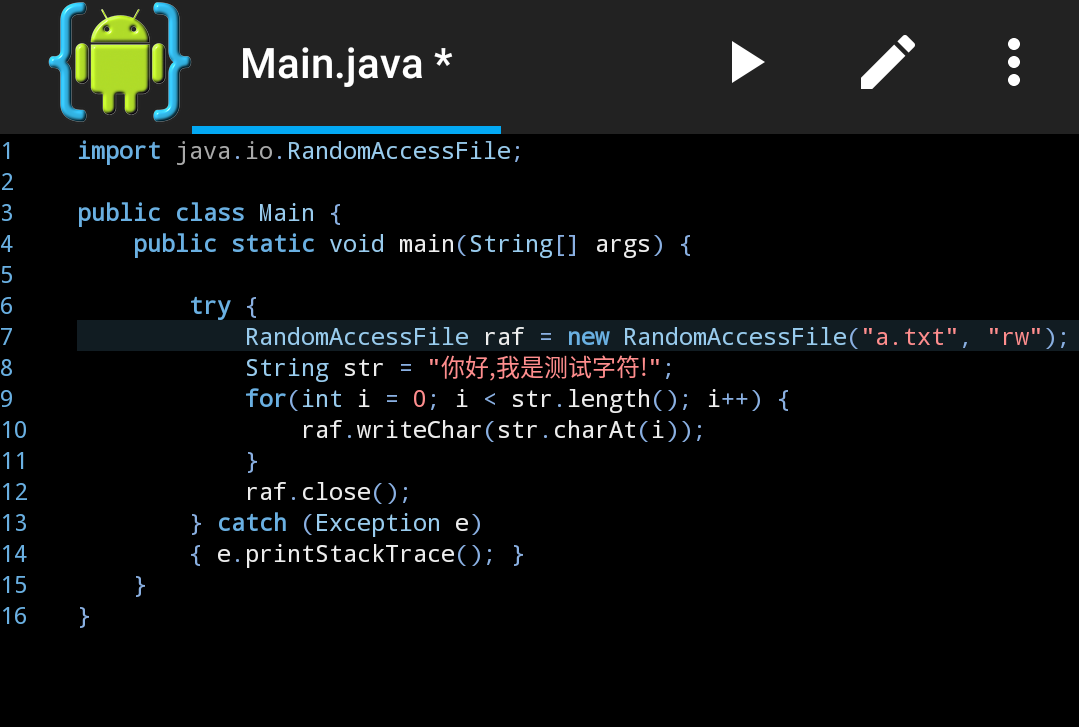
结果如下
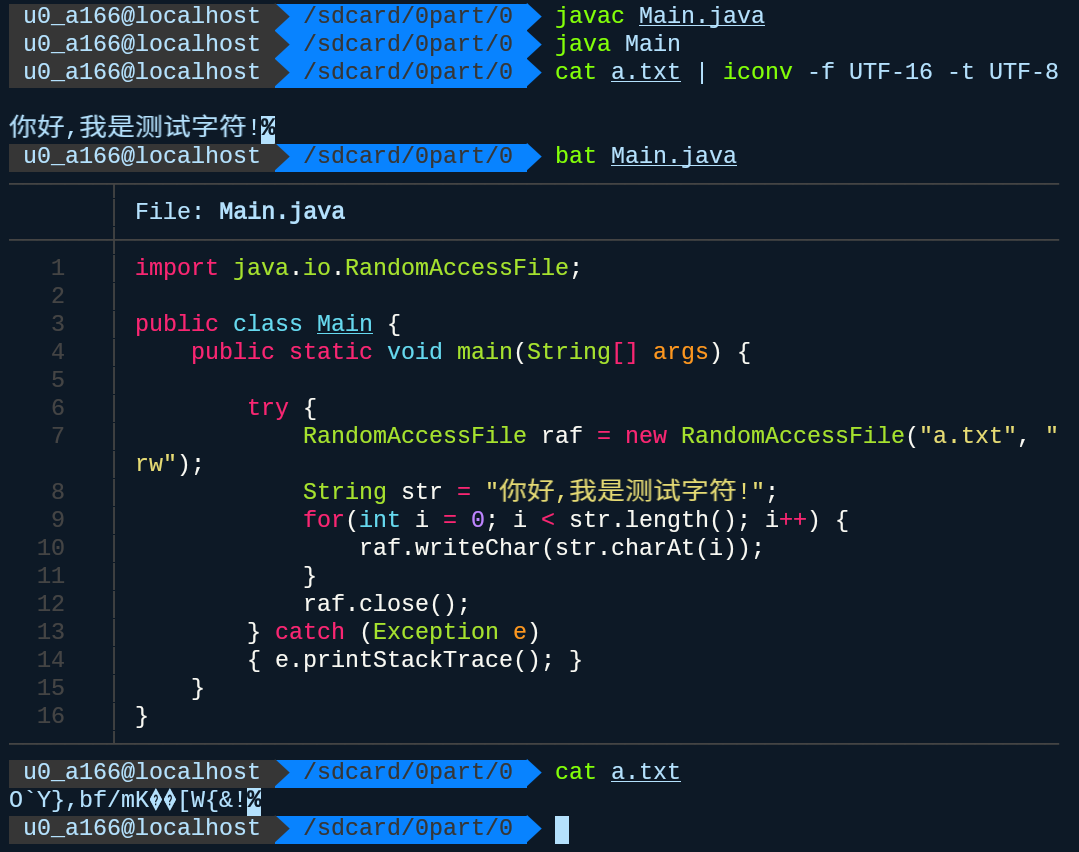
java对字符处理大致如此,在编译时对源文件中的字符串默认使用UTF-8读取,并使用UTF-16存储,注意我们并没有使用System.out.println来输出,因为它会将内部存储的内容转为UTF-8再输出,注意这是在linux系统上,实际上如果是Windows两者的默认都是ANSI,对我们而言就是GBK,Windows命令行默认就是GBK
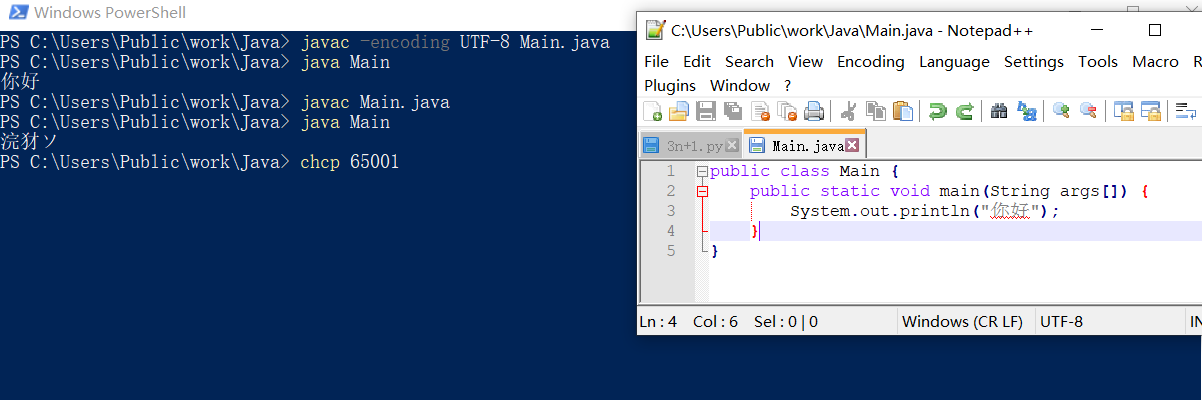
这样的好处是我们只需要考虑源文件的编码格式即可得到正常的调试结果。同时得益于此,我们可以实现简单的编码转化,使用char作为中间形式,new String(inData, sourceEncoding).getBytes(targetEncoding);我们强调输入的数据inData为byte数组数据,实际上对于读入数据java提供了字节流和字符流,字符流输入数据是需要编码的,虽说有时没写,但那是因为系统已经加了一个默认读入编码,同时字符流本质还是通过字节流来读数据的,就像C那样,FileReader继承至我们的转化流InputStreamReader,它是两者流的过度可以传入一个编码。java存储的本质是byte而不是char,不过C/C++里确实是char就是了,而对于源文件里写的字符,与之相关的应是编译时的编码,而非内部的编码转化。
结尾
由上面许多的分析,我有理由认为中文编程语言属实有点造作,中文并不像属于ASCII的英文具有强大的字符兼容性,还只占一个字节。同时与键盘对应的也是ASCII码,从输入效率英语还是比较高。为什么变量命名也推荐英语,大概也是如此,国际化大概就是使用英语做占位符,根据不同的语言集输出不同的内容。最后对编码的分析,我们只需要注意两点,如何编码决定存储方式和如何读出决定显示结果。