lua通读之lua的基本使用
前言
lua是我最喜欢的脚本语言,没有之一。主要还是它轻巧,并包含了程序设计最基本的内容,而且基本没有多余的扩展库,也致使了它强大的扩展性。虽然我最早接触lua是学习cocos2dx游戏引擎的时候,但我却对它终身难望。不过如今的时代,lua或许已经无法满足如今快速开发的时代需求了,cocos2dx的原生版本也因无法高效地开发3A大作而永远定格在了4.0。但想起以前使用lua的日子,我决定写下这个系列,以此纪念当初研究技术的时光。
基本的开发环境
Ubuntu20.04,Android7.1.1+Termux,lua5.1
关于使用lua5.1的说明:
首先5.1是lua的一次大变革版本,其次许多扩展都基于此版本,最后后来版本的变化不大。
lua的基本内容
下载lua5.1.5源码,然后直接make编译,我们可以得到一下核心文件:
1 | #lua的头文件,用于嵌入开发 |
lua用于直接解释lua脚本,luac用于将lua脚本编译为在lua虚拟机上的字节码文件。关于下部分以后讲,我们先专注于lua的基本内容。
lua的基本使用
一些废话
如果讲一门语言的使用,从变量的基本使用讲到控制语句,再讲一些如面向对象,反射等的使用的话,我认为这是在讲程序设计而非一门语言,这些都是任何语言都具备的基本内容,无非是写法的不同罢了。你跟我讲lua没有switch语句,不能var++运算,C语言没有面向对象,C++没有反射机制,还有go那”奇怪”的变量声明,python的强制缩进,object-C的奇特风格语句。后面写的有点离谱了,但事实上,各种语言的一些特性其实记住就行了,在我看来这算不算学习。我们通过lua来讲讲,学习一门语言的核心是什么。
数据的存在形式
引入
我最早学习的语言是java,可能是教程不行,我一直不知道对于数组使用=传递的是引用,因为它们和int,String之类的似乎没什么区别——可以直接声明出来,因为String基本用于存储不变的字符串,基本不会遇到问题。所以导致了可以运行,但结果怎么也不对的bug,这才是最让人奔溃的事情。如今很多的人崇尚面向对象,讨厌指针,大多都是被那种为了教育而编制的离谱而脱离实际的指针题目给吓怕了,比如C++的模板和运算符的重载,真的有使用的必要吗?说实话,除了写起来简便,它基本没有意义。不过将typedef和#define用于版本兼容还是有必要的。
正文
本来应该从源码角度来说明数据类型,不过为了多写几篇,就算了。
在编程里面,产生数据有两种方式,一种是立即数据,一种是变量存储的数据。这可以直接从两种代码直接理解:
1 | #立即数据 "Hello World" |
或许你的感觉不太深,但如果是这样的python代码可能就有些感觉了:
1 | ' '.join(['Hello', 'World']) |
在这里‘ ’就返回了一个string的对象。
不论是立即数据还是变量存储的数据,我们需要关注的是它的返回和在程序中的存在形式。
数据的存在形式只有两种,一是基本数据类型,二是引用数据类型,或者固定大小与可变大小,或者非指针数据与指针数据。比较特别的是string,不过是在其它语言里面,在c系列里,我们应该理解string的长度也是不可变的。
对于lua,nil、布尔和字符串类型都比较简单,就直接跳过了,我们先说一下lua的数字类型。在此之前,不知有没有人把浮点数就认为是小数的,其实我以前也有这个错误的认识,但事实上,浮点数等同于用科学计数法表示的数,可以是大整数也可以是小数,lua的数字本质是double类型,可以在lua的源码里面看出来,lua有自己的一套数字管理体系,但数字大到一定程度会自动用科学计数法表示为浮点数,比如下面的代码:
1 | a = 9999999999999999999999999999999999999999999999999 |
的输出结果一直都是1e+49。对于数据的管理是很重要的,理解机制更加重要,计算机的本质是对数据的处理,如果数据的存储方式不理解的话,就会有许多数据处理的问题。比如在C或Java里面使用int写个大整数的话,还可能出现负数,这其实才是学习一门语言需要真正地关注点,说起这个python可以处理无限大整数确实是有点意思。
感觉接下来说函数闭包和表就有点索然无味了,他两本质都是指针型变量,一个指向函数,一个指向表格数据,也就是说它俩传递的都是引用。函数指针与C语言类似,可以在变量间传递,唯一奇特的就是,这种数据有两种返回方式,一种不加括号返回函数本身,一种加括号返回函数内部return的返回值,如果深入源码,理解Proto的话,可能会知道更多,不过还是留到以后吧。
对于表格,我们需要知道的是其内部有两种存储类型,一种是Hash,另一种是Array,这也对应了两种索引方式,使用string类型的key或者数字。在lua里取出表项的个数的特殊符#,但使用的时候要注意它只能返回Array部分的长度,如下代码:
1 | tab = {1, 2, k=1, b=2} |
返回的结果是2。
插曲
看到这,你或许觉得我说的都没有用处,而且没有学到任何实际的东西。但就如我之前所说,只要学过程序设计,接下来无非就是记住不同的表达,并实践而且熟练罢了。真正痛苦的bug不是无法运行,而是因为理解不深而导致结果与想象不同的bug。而数据存储正占了其中的一大部分,只有理解数据的机制才能防止数据的失真和被优化,在不同语言之中一般都是不同的,这才是我们学习语言该学的东西。
变量的作用域
看下面这段代码:
1 | function fun1() |
发现结果是1。一般代码当然不会这么写,但一旦多起来就会自己搞混了,这里只是举一个例子。与javascript和python这些语言不同,lua默认的作用域是全局,必需声明local 才能局限在函数内。我以前使用cocos2dlua时也因为这个吃了不少亏,才记住了它。我又想说从源码角度理解,算了不要再说了,到时候内容比重就不对了。
输入与返回
lua有种通过函数来封装数据类型的方式,看如下代码:
1 | add = (function () |
打印结果是2,3。怎么样没有晕吧,其实就是通过函数封装了一个变量。外面的add其实是function内部的add通过return返回的结果。其实如果理解lua的数据类型(我之前说的那几种),同时理解程序每段返回什么其实理解起来并不能。这里就是定义了一个函数并执行,然后将返回值传给add。我只能说只可意会不可言传。
到此我基本将lua一些比较核心的有关数据的注意点都讲到了。有句话我很喜欢“程序=数据结构+算法”,正确认识数据在程序中的样子,是发挥出我们构建优质数据结构的基础,而这有是我们设计算法的起点。虽然我也不想当一个“面向API”的程序员,但熟悉一门语言提供的本地api至少可以让你少走弯路。
lua的本地api
没有print(),你的编程就难以开始,所以了解本地api是认识一门语言基本架构的基础。
lua提供了两类api,一种不带前缀如print(),另一种带前缀如math.floor(),以后我们分别称为基本函数和库函数。事实上使用type(math)就可以发现后一种实际上是一个表。点一般不能作为标识符,当然还有像R语言那样的特例。这里我想说一下lua的一个用法,通过表来构建面向对象。
面向对象
面向对象是一种数据存储的方式,封装、继承、多态是其本质。有许多第三方库封装了lua面向对象的特性,但实际上抓住面向对象的本质,自己也是可以构建的。
lua通过表构建的面向对象,不能提供多重的数据保护方式(private,protected,public),实际上这并非很重要,要知道面向对象的语言也是基于面向过程开发的,其目的大概只是为了便于开发,但在大部分的教学里都被神话,属实有点不能理解。以下是一个简单的例子,不过多赘述,顶多注意一下lua语法糖的特性:
1 | local Person = { |
self的作用主要是指向表的变量,因为在表里的函数访问不到同在表内的变量,所以传一个self指针来指向表,你可以回想一下python的面向对象大概也就是这么一回事。
lua本地的全局变量
_VERSION是一个存储当前lua版本的字符串,如我的就是“Lua 5.1”。_G用来存储全局变量的表,所有没有local声明的变量都存在这里,实际上如官方所说没有动的必要,使用_G["print"]()与使用print()是一样的。
lua的本地函数
元表
getmetatable(object)、setmetatable(table,metatable)、rawequal(v1,v2)、rawget(table,index)、rawset(table, index,value)这一系列函数,用来改变表的各种行为,类似于C++的重载,没有必要的话,不推荐使用,使用表封装为对象,用函数代替重载,比较好些。
函数环境
getfenv([f])、setfenv(f,table)之前说过全局变量有张表_G,而调用print等同于调用_G["print"],这些函数就是来改变_G,个人认为通过require分类,比较有用,这个如同元表感觉是没什么大用的东西,事实上也基本没用过,而且后面的版本已经删掉了。
垃圾回收
collectgarbage([opt[,arg]])实际上对于api看官方文档才是正道,它又全面又详细,比我解说几百遍都好。总之就是你不用关注这个,交给系统就行了,除非你需要如jvm一样需要调优。
调试
assert(v[,message])、error(message[, level])类似print不过可以中断程序,输出错误轨迹,但使用库debug可以得到更多信息,所以看个人爱好吧。对于debug库看文档吧。
脚本载入与执行
dofile([filename])、load(func [, chunkname])、loadfile([filename])、loadstring (string[,chunkname])这些基本都是动态解释语言才有的特性,比如javascript的eval(),至于为什么你自己去想想编译原理吧。
遍历表格
ipairs(t)、pairs(t),前一个用来遍历Array部分,后一个用来遍历Hash部分,lua这种共存确实挺神奇的。还有一个next(table[,index]),基本没用过。
包管理
module (name[,···])、require(modname)。这部分还是挺重要的,不过lua一般不做大型项目,除了在cocos2dlua里,基本就没有用过。这可以类比java的package或者C++系列的namespace,又或者python的import。因为语言特性的不同,这些其实都有一定差异。相关配置可以使用package库里的函数。
函数调用
pcall(f,arg1,···)、xpcall(f,err),lua动态语言的体现之一,前后相似,区别在于报错调试。基本没用过。
其它
这些都是lua脚本内常用的函数。print(···)输出到stdout,学习的起点。type(v)类别输出,变量类型可变,需求很大。tonumber(e[,base])、tostring(e)类别转化,百用不腻。select(index,···)参数检验,命令行必备。unpack(list[,i[,j]])表的快捷拆解,数据的福音。都是比喻,不要在意了。
io库
io.*获得对象,通过file:*调用相关函数,通过源码可以知道,相对路径是lua解释器的位置,这值得注意。
math库
math.*提供各项数学运算,数据处理必备,不多言。
os库
os.*提供系统信息,调用系统命令,总之就是很有用。
string库和table库
分别提供字符串与表的处理,用处多大不用我明说。
coroutine库
提供协程操做,这个其实很好理解。将一段代码封装在一个协程里,并提供暂停和回复的操作,用C语言里的goto也能实现,不必要的话还是不用比较好,用队列配合nio的单线程操作效果会更好。
lua的嵌入开发
我认为接下来的内容才是重点,也是lua广泛应用的领域,不过大部分依赖的是luajit,两者区别我以后会从源码给出区别。两种的虚拟机基本差不多,所以讲lua原来的虚拟机有助于以后的理解。
概念
首先我们先来理解一下,lua的嵌入开发是什么意思。我们先明确一点,我们的lua程序只有lua解释器自己一个进程,lua的虚拟机其实是这个进程里的一段数据。
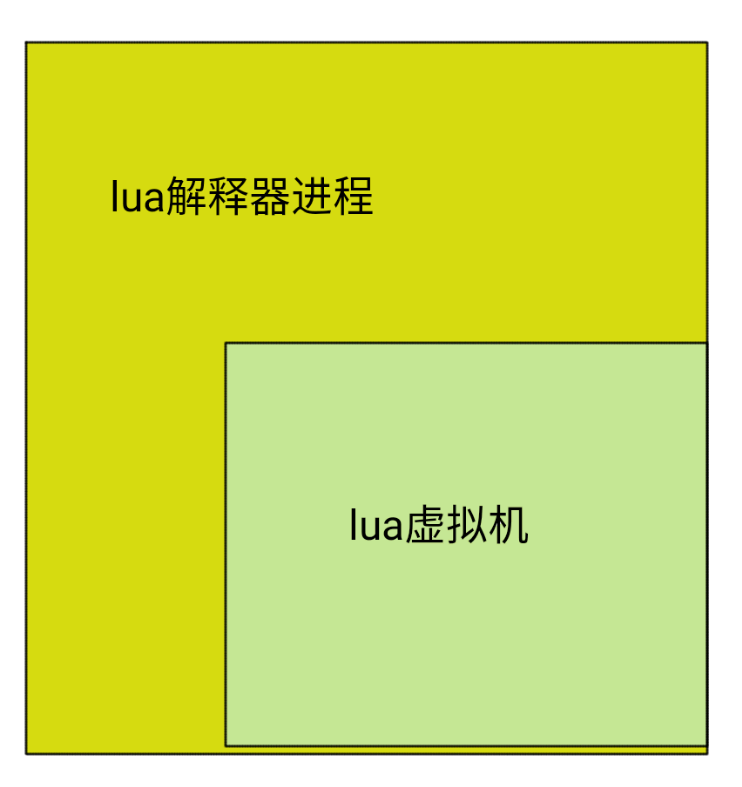
其它部分用来存储解释过程产生的其它数据。所以我们重点关注的是lua的虚拟机,有助于我们开发的部分。所谓lua的嵌入开发主要有两部分,一是从lua脚本中调用C中的函数,另一个是从C中调用lua的函数。对于虚拟机的改造,这属于源码部分,我们以后再讲,我们现阶段的主要目的是将官方文档部分都说一遍。
需要的文件
在lua的全部编译文件里,我们并不需要lua和luac两个文件,我们需要的就4个头文件和1个动态库文件。我们希望自己写一个C语言进程,这个进程来调用lua脚本满足C的一些需求。
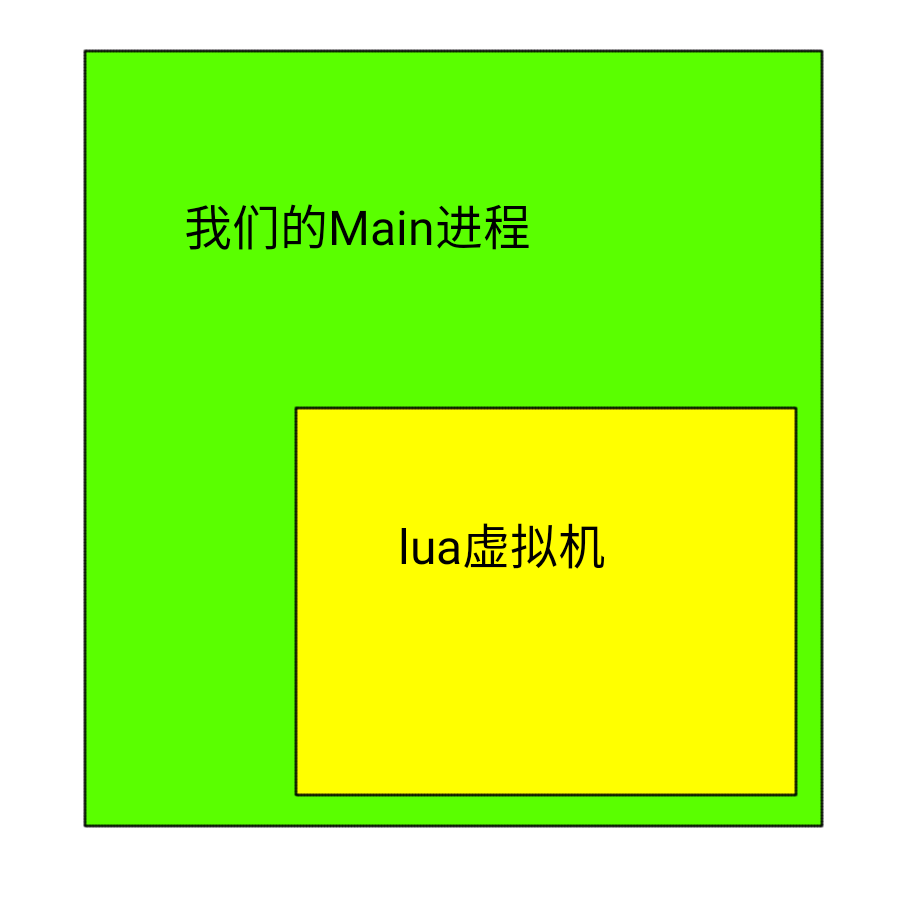
lua与C交互原理
在开发前,我们要清楚lua与C交互的过程是怎么样的。
lua虚拟机核心部分
我们将从开放的C API来展开我们理应关注的部分。大部分C API的第一个参数都是lua虚拟机的指针,这与C没有面向对象的特性有关,也也是为什么要关注lua虚拟机的原因。
lua虚拟机有两个重要部分——TValue组成的栈和一个全局状态机,前者用来存储lua中的各种变量和调用信息,后者用来存储全局信息。TValue由标识类别的int和具体存储数据的联合体组成,也就是说TValue就是lua数据在C源码的具体形式。当然对于数据栈我们持有相应的指针。
C与lua虚拟机的交互
这样可能过于抽象了点,我们来具体实现一个简单的功能来体会一下虚拟机的用法。(我们不会涉及lua脚本,虚拟机的使用本身是C语言的事),我们的目的是在C中实现调用lua中的print并输出“Hello world”,先上源码:
(注:我的lua已经安装到系统了,头文件和库都在系统相应位置,所以可以直接调用,不过为了照顾大家,我就从源码来组织文件)
1 |
|
操作看下面命令行。
我们一句句来看,来理解一下lua在C里的运行方式。
1 | lua_State* L = lua_open(); |
创建一个虚拟机,并导入lua库,我们要使用lua的print,所以第二步是必须的。
1 | lua_getfield(L, LUA_GLOBALSINDEX, "print"); |
从全局表LUA_GLOBALSINDEX处获取print对应的TValue并放入栈顶。lua_getglobal(L, "print");也可以达到同样的效果。
1 | lua_pushstring(L, "Hello World"); |
将字符串“Hello World”推入栈顶。
1 | lua_call(L, 1, 0); |
调用函数一个参数,零个返回值。
这样大致就能了解虚拟机的基本运算机制了,先将要调用的函数入栈,再压入参数,调用函数将返回值入栈到函数位置。这样C语言与lua虚拟的交互大致就能理解了,那么lua脚本又是一个怎样的存在呢?
lua与lua虚拟机
我们将从int lua_load (lua_State *L,lua_Reader reader,void *data,const char *chunkname);这个函数分析lua是怎么进入虚拟机的。事实上,官方的lua程序是通过int luaL_dofile (lua_State *L, const char *filename);这个封装过的函数实现的,但文档下面也说了,它是这样实现的 (luaL_loadfile(L, filename) || lua_pcall(L, 0, LUA_MULTRET, 0))。
我们先来解读参数,第一个跳过,第二个要传入官方指定的一种固定格式的函数Lua_Reader,具体是这样的typedef const char * (*lua_Reader) (lua_State *L, void *data, size_t *size);data是之前调用lua_load里传入的data如果读取文件的话,可以使用文件描述符,size指针用来返回读取了多少数据。等下我给出个简单的例子。load的第三个参数用来表述数据源,但实际上返回结果是通过Lua_Reader的函数,最后一个参数传入名称,跟官方文档lua_load最后会在栈顶产生一个function指针,它的名字就是最后一个参数。一般函数入栈后名字意义不大,主要用于运行是调试定位,我们以后再讲。至此我们已经可以近似实现dofile的功能,代码如下:
1 |
|
1 | print("Hello World") |
结果如下:
全局状态机
对于栈说的差不多了,我们还要讲虚拟机一个比较重要的部分。之前我们讲过lua有一个全局变量_G,这个变量存储了所有的库函数和全局变量(事实上还有_G["_G"]=_G)。在C语言内,我们就可以通过lua_getglobal(key)来获取这个变量相应key对应的值。不过官方给了这个#define lua_getglobal(L,s) lua_getfield(L, LUA_GLOBALSINDEX, s),而lua_getfield()基本不用,就不管了,使用lua_getglobal(L,s)基本可以获得所有的东西了。一个例子就可以带过了:
1 |
|
1 | a = 12 |
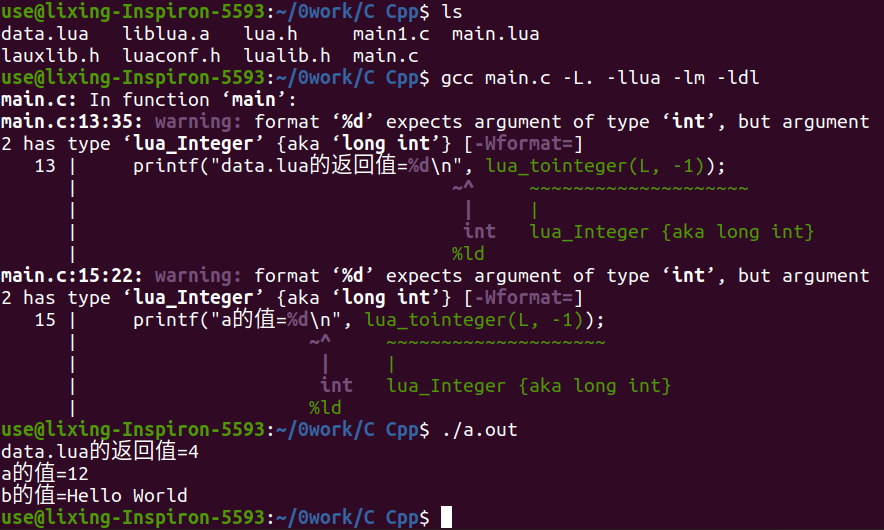
不过还要说一下,C如何往全局状态机写入数据,实际上理解原理以后也是挺简单的,直接给一个例子吧:
1 |
|
1 | print(str) |
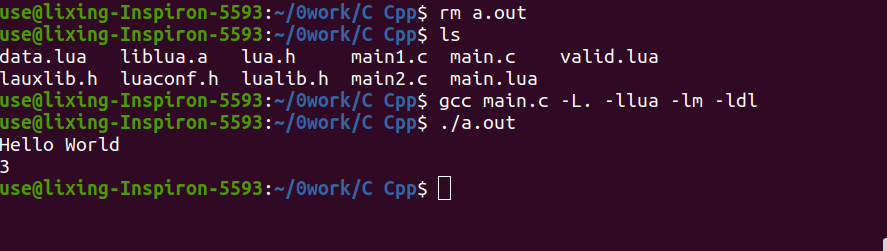
例子是最好的老师,多写多尝试就不会太难。
总结
至此,我们差不多说完了lua和C与虚拟机的基本交互了。我们通过lua_load函数将描述符对应的lua代码打包为一个函数并推入lua虚拟机栈。C则通过对虚拟机栈的操做实现代码的执行。实际上,C语言执行的代码属于lua字节码,在执行lua_load的时候已经将文件编译成了C下可执行的字节码,这个留到以后讲吧。
结尾
到此,我觉得对lua的整体框架已经讲得差不多了,更多的还是得看官方文档,比如lauxlib.h封装了一些便于对虚拟机操作的函数,都值得好好去用以用。就如开始所说,我们虽然不能不学API,但我们不能面向API编程,而应从API去理解运作机理,这样才能更好的使用API。写了这么久,也该结束了。